Configure database storage
9 minute read
KPS data can be stored in a relational database. API Gateway supports the following databases:
- Oracle
- IBM DB2
- Microsoft SQL Server
- MySQL or MariaDB
Note
KPS data defined in Policy Studio supports Cassandra, database, and file data stores. API Manager KPS data (Client Registry and API Catalog) supports Cassandra only.The options for database storage are as follows:
- Shared database storage: Data for multiple KPS tables is stored in a single dedicated database table. Data is encoded in JSON before being stored. This approach is very flexible because it allows maps and lists to be stored in tables. It also minimizes administration overhead because only a single database table needs to be created and managed. This is the recommended approach.
- Per-table database storage Each KPS table is backed by a single database table. Each property in the KPS table maps to a corresponding column in the database table. This approach allows existing tables to be reused, and allows more precise tuning at database level. However, it also has significant limitations (for example, with supported data types and adding and viewing data).
Shared database storage
For shared database storage, a single database table is used to store data for multiple KPS tables. This section describes the storage configuration steps.
Create a KPS database table
Create a database table called kps_object by executing the appropriate SQL script for your database system. SQL scripts are available in the following location:
INSTALL_DIR/system/conf/sql/DB_NAME/kps.sql
Note
For Oracle, ensure that the database is created with the AL32UTF8 character set encoding to support UTF-8.Set up an external connection to the database
To access this table from the API Gateway, you must setup an external database connection from the API Gateway.
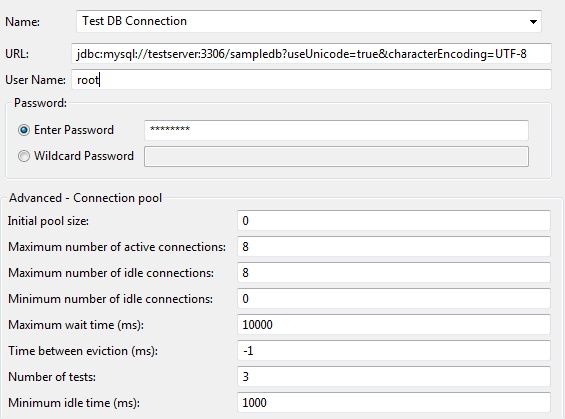
The following shows example database connection settings in Policy Studio:
Note
For MySQL and MariaDB, the table creation script specifies UTF-8. You must also use the correct JDBC connection URL. Update the connection URL field to specify Unicode & UTF-8. For example:jdbc:mysql://testserver:3306/kps?useUnicode=true&characterEncoding=UTF-8
Use the external connection in a KPS collection
When creating a KPS collection, you can select database storage in the Default data source field. The following example shows an SQL database selected:
Alternatively, you can add a database storage option to the collection later. On the Data Sources tab, select Add > Add Database.
For an example with file storage, see Configure file-based KPS storage.
Database storage information
The following describes how KPS data is stored in a database:
- The maximum primary key length in a KPS row is 255 characters
- The maximum KPS table name length is 255 characters
- KPS rows are JSON encoded
- Optimistic locking is used and is enforced using a version column
Increase row size\
You can increase the maximum KPS row size by changing the largeValue column. For example, to support image icons in MySQL or MariaDB, enter the following command:
alter table kps_object modify column largevalue mediumtext;
Logging for shared table storage
Shared database storage uses Apache OpenJPA to handle the communication between KPS and the back-end database. You can use OpenJPA logging to view the SQL requests transmitted to the database and their responses. This information can be useful for debugging. You can configure OpenJPA logging using Apache log4j properties.
Enable OpenJPA debug logging
To enable OpenJPA debug logging:
-
Edit the following file:
INSTALL_DIR/apigateway/system/lib/log4j2.xml -
Add the following settings:
Change the level from "error" to "debug" in all the lines shown bellow: <Root level="info"> <Logger name="org.apache.openjpa.Tool" level="error" additivity="false"> <Logger name="org.apache.openjpa.Runtime" level="error" additivity="false"> <Logger name="org.apache.openjpa.Remote" level="error" additivity="false"> <Logger name="org.apache.openjpa.DataCache" level="error" additivity="false"> <Logger name="org.apache.openjpa.MetaData" level="error" additivity="false"> <Logger name="org.apache.openjpa.Enhance" level="error" additivity="false"> <Logger name="org.apache.openjpa.Query" level="error" additivity="false"> <Logger name="org.apache.openjpa.jdbc.SQL" level="error" additivity="false"> <Logger name="org.apache.openjpa.jdbc.SQLDiag" level="error" additivity="false"> <Logger name="org.apache.openjpa.jdbc.JDBC" level="error" additivity="false"> <Logger name="org.apache.openjpa.jdbc.Schema" level="error" additivity="false"> -
Restart the API Gateway.
-
Verify that debug statements are written to the log.
Disable OpenJPA debug logging
To disable OpenJPA debug logging:
-
Edit the following file:
INSTALL_DIR/apigateway/system/conf/log4j2.xml -
Substitute
ERRORforDEBUGin all theLogger name="org.apache.openjpa.Tool"entries. -
Restart the API Gateway.
-
Verify that no debug statements are printed to the log.
For more information on Apache OpenJPA logging, see the Apache documentation.
Per-table database storage
You can use this option to map a KPS table to a single database table. The structure of both tables must match, so a new database table is required for each new KPS table. When the KPS table is queried, an SQL statement is executed to retrieve the correct row from the underlying database table. This SQL statement is provided by the user in Policy Studio.
Tables that use per-table database storage have significant limitations:
- Data cannot be added through KPS, but only directly through the database
- Data cannot be viewed in
kpsadminor API Gateway Manager, but can only be read by selectors at runtime - Tables can only contain simple data types, not maps or lists
KPS tables can be queried using simple or composite keys. This section shows examples of both.
Map a database table using a single key
In this example, a KPS table is accessed using a single key property. This key is used to retrieve the correct row from the database table. This example uses the following User table and data created using a MySQL client:
CREATE TABLE User (
email VARCHAR(100),
password VARCHAR(100),
firstName VARCHAR(100),
lastName VARCHAR(100),
age INT
);
insert into User (email, password, firstName, lastName, age)
values ("ralph.jones@acme.com", "password", "Ralph", "Jones", 30);
insert into User (email, password, firstName, lastName, age)
values ("kathy.adams@acme.com", "blah", "Kathy", "Adams", 35);
Set up external connection to the database
To access a database from the API Gateway, you must set up an external database connection (see Set up an external connection to the database). This example uses the configuration from Get started with KPS.
Add the database data source to the KPS collection
To add a database data source, perform the following steps:
-
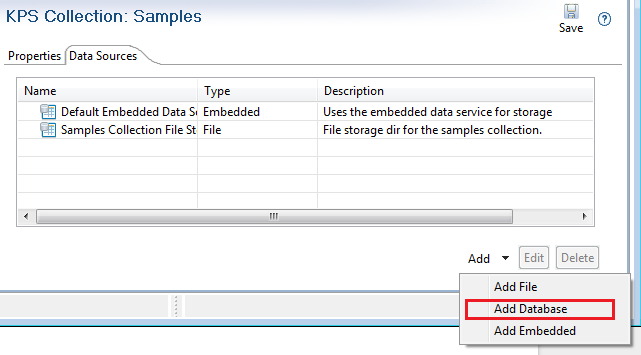
On the KPS collection Data Sources tab, select Add > Add Database.
-
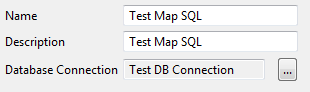
Specify the Database Connection in the dialog (for example, Test DB Connection):
Map the SQL table to a KPS table
From an existing KPS collection, perform the following steps:
-
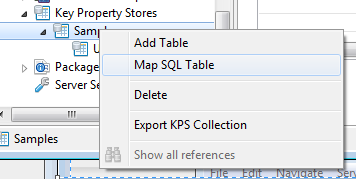
Right-click the KPS collection, and select Map SQL Table:
-
Enter an alias in the dialog (for example
mapUser) :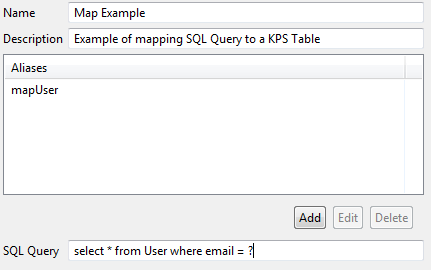
-
Enter a database-specific JDBC SQL query to retrieve the required data. For example:
select * from User where email = ? -
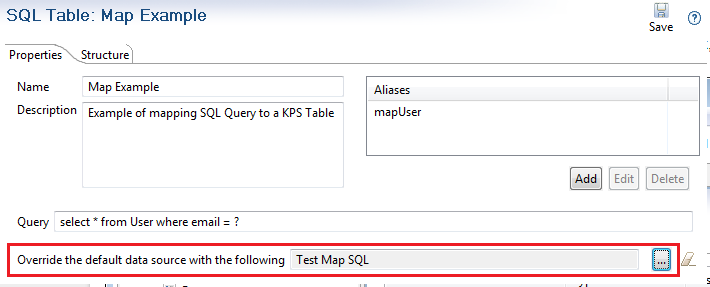
On the Properties tab of the new KPS table, select the new database data source in Override the default data source with the following:
Define the KPS table structure
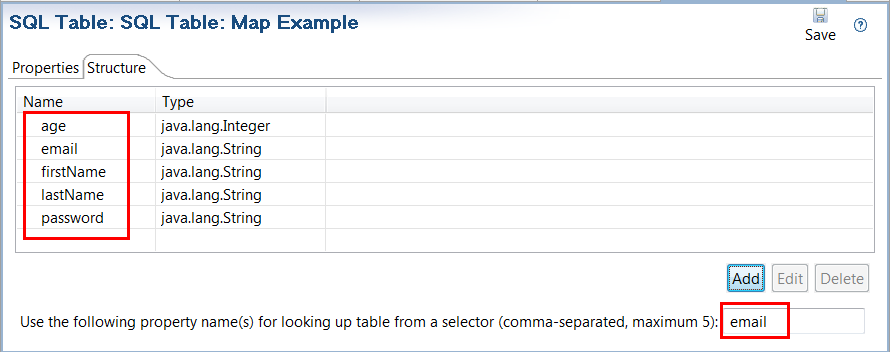
You must define a KPS table structure into which data will be read. You must specify the fields that you expect to read with the SQL query. In this example, all fields in the table are read using an asterisk (*) in the SQL query. This lists all fields, so the order does not matter in this case. However, the names and type must match the result returned by the SQL query.
In this SQL query, email is the primary key. You specify email as the property to use in corresponding selector queries:
For example, you can use the following selector:
${kps.mapUser["kathy.adams@acme.com"].age}
Note
This syntax uses ASCII quotation marks (").This selector generates the following SQL query:
select * from User where email = "kathy.adams@acme.com"
Define the policy and path
You can reuse the policy and path from Get started with KPS with one change—use the mapUser KPS alias for this new table. For example:
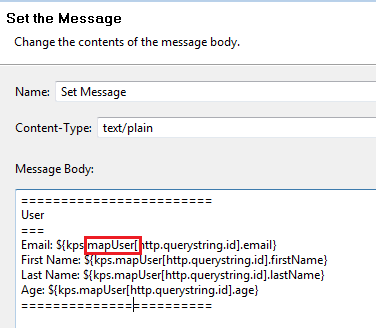
Deploy and run
Click Deploy in the Policy Studio toolbar.
To run the policy in your browser, go to <http://localhost:8080/kpsGetViaSelector?id=kathy.adams@acme.com>
This URL specifies the user ID (email) as kathy.adams@acme.com.
How to map a database table using a composite key
This section modifies the example in map a database table using a single key. This section shows how a table with a composite secondary key can be accessed from a selector. In this version, the secondary key is {firstName, lastName}.
Modify the KPS table
You must update the database-specific JDBC SQL query in the KPS table to retrieve the required data.
To modify the KPS table, perform the following steps:
-
On the Properties tab in the Query field, enter the following:
select * from User where firstName = ? and lastName = ?For example:
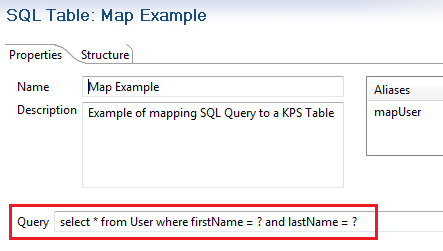
-
On the Structure tab, change the selector properties to
firstName,lastName: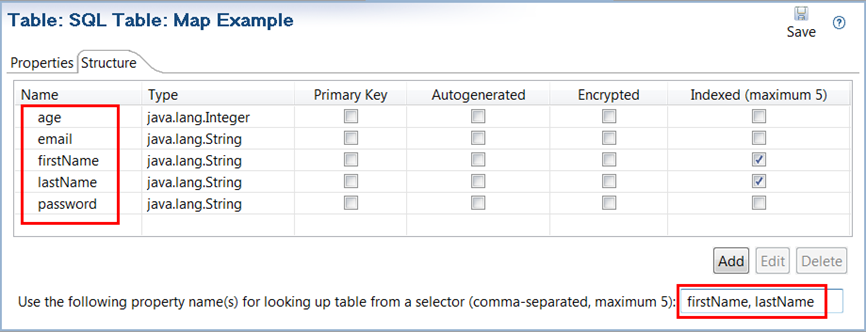
Modify the policy
You must update the Set Message filter in your policy to use firstName and lastName parameters. For example:
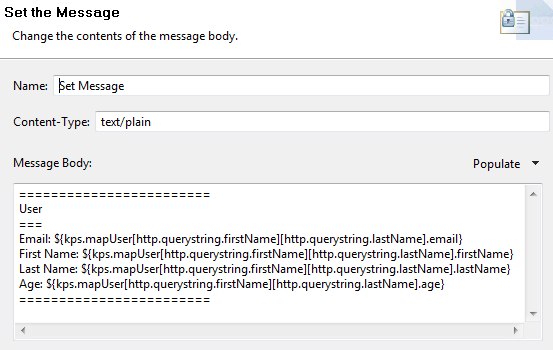
Enter the following in the Message Body field, using a single line for each entry (Email, First Name, Last Name, and Age):
========================
User
===
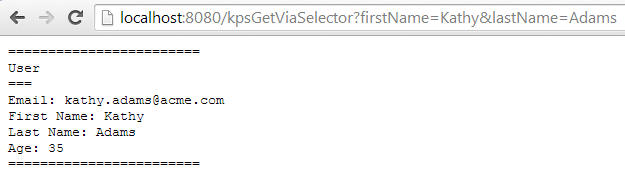
Email: ${kps.mapUser[http.querystring.firstName][http.querystring.lastName].email}
First Name: ${kps.mapUser[http.querystring.firstName][http.querystring.lastName].firstName}
Last Name: ${kps.mapUser[http.querystring.firstName][http.querystring.lastName].lastName}
Age: ${kps.mapUser[http.querystring.firstName][http.querystring.lastName].age}
========================
Deploy and run the policy
Click Deploy in the Policy Studio toolbar.
To run the policy in a browser, go to the following URL: <http://localhost:8080/kpsGetViaSelector?firstName=Kathy&lastName=Adams>
For example, the result is as follows:
Configure Apache Cassandra KPS storage
Apache Cassandra provides a highly available (HA) data storage option for KPS. API Gateway can connect to an external Cassandra database cluster. You must configure three Cassandra nodes to provide a HA data service. A default single Cassandra node, non-HA system typically does not require additional configuration.
Note
Custom KPS data defined in Policy Studio supports Cassandra, database, and file data stores. However, API Manager KPS tables (Client Registry and API Catalog) support Cassandra only. Database and file data stores are not supported for API Manager. Three-node Cassandra HA with full consistency is required for API Manager.For details on installing and configuring Apache Cassandra HA for API Gateway and API Manager, see Configure a highly available Cassandra cluster.
Configure file-based KPS storage
You can store KPS data in a directory on the file system. Each table is stored in a single JSON file. File-based storage is specified at the KPS collection or KPS table level.
Note
File-based KPS storage is deprecated and will be removed in a future release.File-based KPS storage is most suited to single API Gateway deployments. In a multi-API Gateway scenario, file replication or a shared disk is required to ensure that all API Gateways use the same data.
KPS data defined in Policy Studio supports Cassandra, database, and file data stores. API Manager. KPS data (Client Registry and API Catalog) supports Cassandra only.
File-based KPS tables are read and cached by API Gateways when they start up. If data is modified, all API Gateways must be restarted to pick up the changes.
Configure a file-based KPS collection
You can configure a file-based KPS data source when creating a KPS collection, or add one later on the Data Source tab. For example, the following settings are available when editing file-based collection:
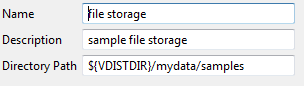
These settings are described as follows:
| Name | Description |
|---|---|
| Name | Collection-unique data source name. |
| Description | Optional description. |
| Directory Path | The directory name where table data for the collection is stored. If the directory does not exist, it is automatically created. If this directory is not specified, the directory path defaults to ${VINSTDIR}/conf/kps. The path can include VDISTDIR or VINSTDIR variables. These are resolved to the API Gateway instance and installation directories. For example, ${VDISTDIR}/mydata/samples. Remember to use the correct path separator (/ on Linux). |