Apache Cassandra backup and restore
13 minute read
In an Apache Cassandra database cluster, data is replicated between multiple nodes and potentially between multiple datacenters. Cassandra is highly fault-tolerant, and depending on the size of the cluster, it can survive the failure of one or more nodes without any interruption in service. However, backups are still needed to recover from the following scenarios:
- Any errors made in data by client applications.
- Accidental deletions.
- Catastrophic failure that requires a rebuild of the entire cluster.
- Rollback of the cluster to a known good state in the event of data corruption.
This topic describes which Apache Cassandra data keyspaces to back up, and explains how to use scripts to create and restore the data in those keyspaces. It also describes which Apache Cassandra configuration and API Gateway configuration to back up.
Caution
You must read the following before you perform any of the instructions in this topic:
- These instructions apply only to an Apache Cassandra cluster where the replication factor is the same as the cluster size, which means that each node contains 100% of the data. This is the standard configuration for Axway API Management processes, and these instructions are intended to back up API Management keyspaces only.
- Because 100% of the data is stored on each node, you will run the backup procedure on a single node only, preferably on the seed node.
- The following instructions and scripts are intended as a starting point and must be customized and automated as needed to match your backup polices and environment.
- These instructions use the Cassandra snapshot functionality. A snapshot is a set of hard links for the current data files in a keyspace. While the snapshot does not take up noticeable diskspace, it will cause stale data files not to be cleaned up. This is because a snapshot directory is created under each table directory and will contain hard links to all table data files. When Cassandra cleans up the stale table data files, the snapshot files will remain. Therefore, it is critical to remove them promptly. The example backup script takes care of this by deleting the snapshot files at the end of the backup.
- For safety reasons, the backup location should not be on the same disk as the Cassandra data directory, and it also must have enough free space to contain the keyspace.
Which data keyspaces to back up?
These procedures apply to data in API Management and KPS keyspaces only.
You must first obtain a list of the keyspace names to back up. API Management keyspaces may have a custom name defined, but they are named in the format of <UUID>_group_[n] by default. For example:
x9fa003e2_d975_4a4a_a27e_280ab7fd8a5_group_2p_2
All Cassandra internal keyspaces begin with system, and should not be backed up using this process. You can do this using cqlsh or kpsadmin commands:
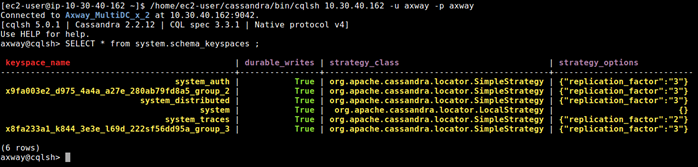
Find keyspaces using cqlsh
Using cqlsh, execute the following command:
SELECT * from system.schema_keyspaces;
In the following example, xxx_group_2 and xxx_group_3 are API Management keyspaces:
Find keyspaces using kpsadmin
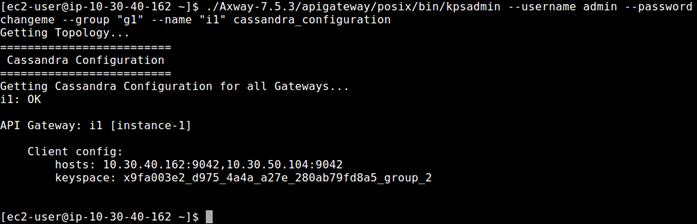
Using kpsadmin, choose: option 30) Show Configuration, and enter the API Gateway group and any instance to back up, or use the command line, as shown in the following example:
Back up or restore Cassandra using the backup tool
The API Gateway backup tool is located in install_dir/apigateway/tools/apigw-backup-tool. To get started, you must copy the apigw-backup-tool folder to your Cassandra seed node.
Update your configuration file
Update the /conf/apigw-backup-tool.ini file to configure your backup.
The following table describes the parameters in the apigw-backup-tool.ini file:
| Configuration Name | Description |
|---|---|
| cassandra_data_dir | Directory which stores the Cassandra data, usually cassandra/data/data |
| cassandra_commitlog_dir | Directory which stores Cassandra commit logs, usually cassandra/data/commitlog |
| cassandra_saved_caches_dir | Directory which stores Cassandra saved cache, usually cassandra/data/saved_caches |
| cqlsh_bin | Path to the cqlsh utility, usually cassandra/bin/cqlsh |
| nodetool_bin | Path to the nodetool utility, usually cassandra/bin/nodetool |
| cqlsh_ip | IP address used by the cqlsh |
| cql_username | Username used by the cqlsh |
| cql_password | Password used by the cqlsh |
| nodetool_username | Username used by the nodetool |
| nodetool_password | Password used by the nodetool |
| backup_root_dir | Path to the backup directory |
| printcmd | Set to true to see the commands ran by the tool during the process |
| debug | Set to true to see debug logs |
After the configuration is set and Cassandra is running, run the following command to validate the configuration:
apigw-backup-tool validateConfig
Back up your Cassandra keyspace
While Cassandra is running, run the following command to create a backup in the backup_root_dir folder:
apigw-backup-tool backup -k <keyspace name> -s <snapshot name>
After the backup is complete, it can be found in the following structure:
<BACKUP_ROOT_DIR>
├── <BACKUP_SNAPSHOT_NAME>
│ ├── <SNAPSHOT_NAME>
│ │ ├── <TABLE_NAME>
│ │ │ ├── <SNAPSHOT_FILES>
│ │ ├── <TABLE_NAME>
│ │ │ ├── <SNAPSHOT FILES>
│ │ │...
Use your company’s archive method to archive the BACKUP_SNAPSHOT_NAME directory, so you can restore it later if needed.
Restore the keyspace backup
If you are restoring the keyspace in a new Cassandra cluster, you must ensure the following before you start this task:
- The backup snapshot must only contain data from the tables and columns in the keyspace schema.
- The Cassandra cluster must be created in a highly available Cassandra cluster.
- All API Gateway groups must have their schema created in the new cluster, and the replication factor must be the same as the cluster size (normally,
3).
To restore a keyspace:
-
Shut down all API Gateway instances and any other clients in the Cassandra cluster.
-
Run the following command:
apigw-backup-tool restore -k <keyspace name> -s <snapshot name>- The tool will perform several tasks to restore the cluster. The process can take time, depending on the amount of data in the backup.
- The tool will prompt the user to perform manual actions on other nodes in the cluster
Note
You must read the manual actions carefully. Some actions need to be performed on every node of the cluster, others only on the other nodes (not on the one where the script is running).Back up and restore a cluster with multiple nodes
To back up and restore a 3-node cluster into a new 3-node cluster.
-
To create the backup, copy the
apigw-backup-toolfolder to the seed node of both the old and the new cluster. -
Configure the
apigw-backup-toolin both the old and the new clusters, then verify that the configuration is correct:apigw-backup-tool validateConfig -
Run the backup script on the old cluster:
apigw-backup-tool backup -k <keyspace name> -s <snapshot name> -
Copy the backup folder to the new cluster. The backup must be copied to the
backup_root_dirdirectory that is configured in new cluster. -
In the new cluster, run the restore script:
apigw-backup-tool restore -k <keyspace name> -s <snapshot name>
Note
The actions of starting and stopping Cassandra are not handled by the script, which mean you will need to perform them manually when the script ask you to.To restore a backup of multiple nodes taken in the same cluster, ensure the backup is in backup_root_dir, and run the restore command.
apigw-backup-tool restore -k <keyspace name> -s <snapshot name>
If data exists in the cluster, the script will prompt you to remove it and start fresh. If you decide not to remove the keyspace, the script will abort.
Use cqlsh to back up a keyspace schema
To export the keyspace schema, run the following command:
cqlsh IP_ADDRESS -u username -p password -e "DESC keyspace KEYSPACE_NAME" > KEYSPACE_NAME_schema_backup.cql
Back up a keyspace manually
To manually back up a keyspace, you must use the nodetool snapshot command to create hard links, run a custom script to back up these links, then archive that backup.
- It is recommended to take a snapshot backup on a daily basis.
- You must repeat these steps for each keyspace to back up.
-
Create a snapshot by running the following command on the seed node:
nodetool CONNECTION_PARMS snapshot -t SNAPSHOT_NAME-TIMESTAMP API_GW_KEYSPACE_NAME -
Run the Cassandra snapshot backup script to copy the snapshot files to another location:
Note
This script also clears the snapshot files from the Cassandradatadirectory.When this script finishes, it creates the following backup directory structure:
<BACKUP_ROOT_DIR> ├── <SNAPSHOT_NAME> │ ├── <TABLE_NAME> │ │ ├── <SNAPSHOT_FILES> │ ├── <TABLE_NAME> │ │ ├── <SNAPSHOT FILES> │ │... -
Archive the
SNAPSHOT_NAMEdirectory using your company’s archive method so you can restore it later if needed.
Sample Cassandra snapshot backup script
#!/bin/bash
################################################################################
# Sample Cassandra snapshot backup script #
# NOTE: This MUST be adapted for and validated in your environment before use! #
################################################################################
set -e
trap '[ "$?" -eq 0 ] || echo \*\*\* FATAL ERROR \*\*\*' EXIT $?
# Replace the xxx values below to match your environment
CASSANDRA_DATA_DIR="xxx"
KEYSPACE_NAME="xxx"
SNAPSHOT_NAME="xxx"
BACKUP_ROOT_DIR="xxx"
# Example:
# CASSANDRA_DATA_DIR="/opt/cassandra/data/data"
# KEYSPACE_NAME="x9fa003e2_d975_4a4a_a27e_280ab7fd8a5_group_2"
# SNAPSHOT_NAME="Group2-20181127_2144_28"
# BACKUP_ROOT_DIR="/backup/cassandra-snapshots"
##### Do NOT change anything below this line #####
backupdir="${BACKUP_ROOT_DIR}/${SNAPSHOT_NAME}"
if [ -d "${backupdir}" ]; then echo -e "\nERROR: Snapshot '${SNAPSHOT_NAME}' already exists in the backup dir";exit 1; fi
mkdir -p ${backupdir}
keyspace_path="${CASSANDRA_DATA_DIR}/${KEYSPACE_NAME}"
if ! [ -d "${keyspace_path}" ]; then echo -e "\nERROR: Keyspace path '${keyspace_path}' is not valid";exit 1; fi
snapshot_dirs=()
find "${keyspace_path}/" -maxdepth 1 -mindepth 1 -type d ! -name "$(printf "*\n*")" > backup.tmp
while IFS= read -r table_dir
do
str=${table_dir##*/}
table_uuid=${str##*-}
len=$((${#str} - ${#table_uuid} - 1))
table_name=${str:0:${len}}
echo "Copy table, $table_name"
current_backup_dir="${backupdir}/${table_name}"
mkdir -p "${current_backup_dir}"
current_snapshot="${table_dir}/snapshots/${SNAPSHOT_NAME}"
snapshot_dirs+=("${current_snapshot}")
cp -r -a "${current_snapshot}"/* "${current_backup_dir}/"
done < backup.tmp
rm backup.tmp
echo -e "\nRemoving snapshot files from Cassandra data directory"
for dir in "${snapshot_dirs[@]}"
do
rm -rf "${dir}"
done
Restore a keyspace schema manually
For the restore to be successful, the backup snapshot data must only contain data from the tables and columns in the keyspace schema. This is only necessary if the schema is not already present, for example, if setting up a new cluster as a copy of an existing cluster.
The keyspace schema can be restored one of two ways:
- API Gateway will create a new keyspace when deploying a configuration with KPS tables and a Cassandra connection. If the schema already exists, API Gateway will create all tables that do not exist in the current keyspace schema.
- Open
cqlshin the directory that contains the CQL file containing the backup, and run the following command to restore an existing keyspace schema backup:
source 'KEYSPACE_NAME_schema_backup.cql';
Restore API Management and KPS keyspaces manually
This section explains how to restore API Management and KPS keyspaces, and provides an example script to restore the files.
Note
If you are restoring a keyspace to the same cluster that the backup was taken from, skip to Steps to restore a keyspace.Before you restore a keyspace in a new Cassandra cluster, you must ensure the following:
- The Cassandra cluster must be created to the API Gateway HA specifications. For more details, see Configure a highly available Cassandra cluster.
- All API Gateway groups must have their schema created in the new cluster, and the replication factor must be the same as the cluster size (normally 3).
- If the keyspace name has changed in the new cluster, use the new name in the
KEYSPACE_NAMEvariable in the restore script.
To manually restore a keyspace:
-
Shut down all API Gateway instances and any other clients in the Cassandra cluster.
-
Drain and shut down each Cassandra node in the cluster, one node at a time.
Caution
Wait for it to complete on each Cassandra node before shutting it down, otherwise data loss may occur:nodetool CONNECTION_PARMS drain -
On the Cassandra seed node, delete all files in the
commitlogandsaved_cachesdirectory.For example:
rm -r /opt/cassandra/data/commitlog/* /opt/cassandra/data/saved_caches/*Caution
Do not delete any folders in the keyspace folder on the node being restored. The restore script requires the table directories to be present in order to function correctly. -
On the Cassandra seed node, run the Cassandra restore snapshot script to restore the snapshot files taken by the backup process and script.
-
On the other nodes in the cluster, perform the following:
- Delete all files in the
commitlogandsaved_cachesdirectory. - Delete all files in the
KEYSPACEbeing restored under theCASSANDRA_DATA_DIRECTORY. For example:
rm -rf /opt/cassandra/data/data/x9fa003e2_d975_4a4a_a27e_280ab7fd8a5_group_2/* - Delete all files in the
-
If you have other keyspaces to restore, return to step 4 and repeat. Otherwise, continue to the next steps.
-
One at a time, start the Cassandra seed node, and then the other nodes, and wait for each to be in Up/Normal (
UN) state innodetool statusbefore you proceed to the next node. -
Perform a full repair of the cluster as follows on each node one at a time:
nodetool repair -pr --full -
On the Cassandra seed node, run the Cassandra reload the indexes script.
-
Start the API Gateway instances.
Sample Cassandra restore snapshot script
#!/bin/bash
################################################################################
# Sample Cassandra restore snapshot script #
# NOTE: This MUST be adapted for and validated in your environment before use! #
################################################################################
# Replace the xxx values below to match your environment
CASSANDRA_DATA_DIR="xxx"
KEYSPACE_NAME="xxx"
SNAPSHOT_NAME="xxx"
BACKUP_ROOT_DIR="xxx"
# Example:
# CASSANDRA_DATA_DIR="/opt/cassandra/data/data"
# KEYSPACE_NAME="x9fa003e2_d975_4a4a_a27e_280ab7fd8a5_group_2"
# SNAPSHOT_NAME="Group2-20181127_2144_28"
# BACKUP_ROOT_DIR="/backup/cassandra-snapshots"
##### Do NOT change anything below this line #####
backupdir="${BACKUP_ROOT_DIR}/${SNAPSHOT_NAME}"
keyspace_path="${CASSANDRA_DATA_DIR}/${KEYSPACE_NAME}"
echo -e "\n\tRestoring tables from directory, '${backupdir}', to directory, '${keyspace_path}'"
echo -e "\tRestore snapshot, '${SNAPSHOT_NAME}', to keyspace, '${KEYSPACE_NAME}'"
read -n 1 -p "Continue (y/n)?" answer
echo -e "\n"
if [ "$answer" != "y" ] && [ "$answer" != "Y" ]; then
exit 1
fi
set -e
trap '[ "$?" -eq 0 ] || echo \*\*\* FATAL ERROR \*\*\*' EXIT $?
if ! [ -d "${backupdir}" ]; then echo -e "\nERROR: Backup not found at '${backupdir}'";exit 1; fi
if ! [ -d "${keyspace_path}" ]; then echo -e "\nERROR: Keyspace path '${keyspace_path}' is not valid";exit 1; fi
keyspace_tables=$(mktemp)
find "${keyspace_path}/" -maxdepth 1 -mindepth 1 -type d -fprintf ${keyspace_tables} "%f\n"
sort -o ${keyspace_tables} ${keyspace_tables}
backup_tablenames=$(mktemp)
find "${backupdir}/" -maxdepth 1 -mindepth 1 -type d -fprintf ${backup_tablenames} "%f\n"
sort -o ${backup_tablenames} ${backup_tablenames}
keyspace_tablenames=$(mktemp)
table_names=()
table_uuids=()
while IFS= read -r table
do
str=${table##*/}
uuid=${str##*-}
len=$((${#str} - ${#uuid} - 1))
name=${str:0:${len}}
echo "${name}" >> ${keyspace_tablenames}
table_names+=(${name})
table_uuids+=(${uuid})
done < ${keyspace_tables}
set +e
sort -o ${keyspace_tablenames} ${keyspace_tablenames}
diff -a -q ${keyspace_tablenames} ${backup_tablenames}
if [ $? -ne 0 ]; then
echo -e "\nERROR: The tables on the keyspace at, '${keyspace_path}', are not the same as the ones from the backup at,
'${backupdir}'"
exit 1
fi
for ((i=0; i<${#table_names[*]}; i++));
do
echo "Restoring table, '${table_names[i]}'"
table_dir="${keyspace_path}/${table_names[i]}-${table_uuids[i]}"
rm -r "${table_dir}"
mkdir "${table_dir}"
src="${backupdir}/${table_names[i]}"
cp -r -a "${src}"/* "${table_dir}/"
done
Sample Cassandra reload the indexes script
#!/bin/bash
################################################################################
# Sample Cassandra reload indexes script #
# NOTE: This MUST be adapted for and validated in your environment before use! #
################################################################################
# Replace the xxx values below to match your environment
CASSANDRA_BIN_DIR="xxx"
KEYSPACE_NAME="xxx"
NODETOOL_ARGS=""
CQLSH_ARGS=""
# Example:
# CASSANDRA_BIN_DIR="/opt/cassandra/bin"
# KEYSPACE_NAME="x9fa003e2_d975_4a4a_a27e_280ab7fd8a5_group_2"
# NODETOOL_ARGS="-u username -pw password"
# CQLSH_ARGS="-u username -p password"
##### Do NOT change anything below this line #####
cqlsh="${CASSANDRA_BIN_DIR}/cqlsh ${CQLSH_ARGS}"
nodetool="${CASSANDRA_BIN_DIR}/nodetool ${NODETOOL_ARGS}"
echo -e "\n\tRebuilding indexes - all indexes will be rebuilt using nodetool rebuild_index"
echo -e "\tRebuild indexes for keyspace ${KEYSPACE_NAME}?"
read -n 1 -p "Continue (y/n)?" answer
echo -e "\n"
if [ "$answer" != "y" ] && [ "$answer" != "Y" ]; then
exit 1
fi
set -e
trap '[ "$?" -eq 0 ] || echo \*\*\* FATAL ERROR \*\*\*' EXIT $?
if ! [ -d "${CASSANDRA_BIN_DIR}" ]; then echo -e "\nERROR: Cassandra bin dir not found at '${CASSANDRA_BIN_DIR}'";exit 1; fi
indexes=$(mktemp)
${cqlsh} -e "SELECT columnfamily_name, index_name FROM system.schema_columns WHERE keyspace_name = '${KEYSPACE_NAME}'" > ${indexes}
sed -i -e '1,3d;/^$/d;s/[[:blank:]]\{1,\}/ /g;s/|//;/null/d;$d' ${indexes}
if [ $(wc -l < ${indexes}) -eq 0 ]; then
echo -e "Error getting current indexes"
exit 1
fi
while IFS= read -r line
do
index="${line#"${line%%[![:space:]]*}"}"
echo -e "Rebuilding index: '${index}'"
${nodetool} rebuild_index ${KEYSPACE_NAME} ${index}
echo -e "\tDone"
done < "$indexes"
Which configuration to back up?
In addition to backing up your data in Apache Cassandra keyspaces, you must also back up your Apache Cassandra configuration and API Gateway configuration.
Apache Cassandra configuration
You must back up the CASSANDRA_HOME/conf directory on all nodes.
API Gateway group configuration
You must back up the API Gateway group configuration in the following directory:
API_GW_INSTALL_DIR/apigateway/groups/<group-name>/conf
This directory contains the API Gateway, API Manager, and KPS configuration data.
Migrating data between environments
Encrypted KPS data cannot be transferred directly between environments, so to migrate data between environments you must re-encrypt the KPS data.