Multi-datacenter failover scenarios
3 minute read
One API Gateway instance is down
In this case, one API Gateway instance is down in DC 1:
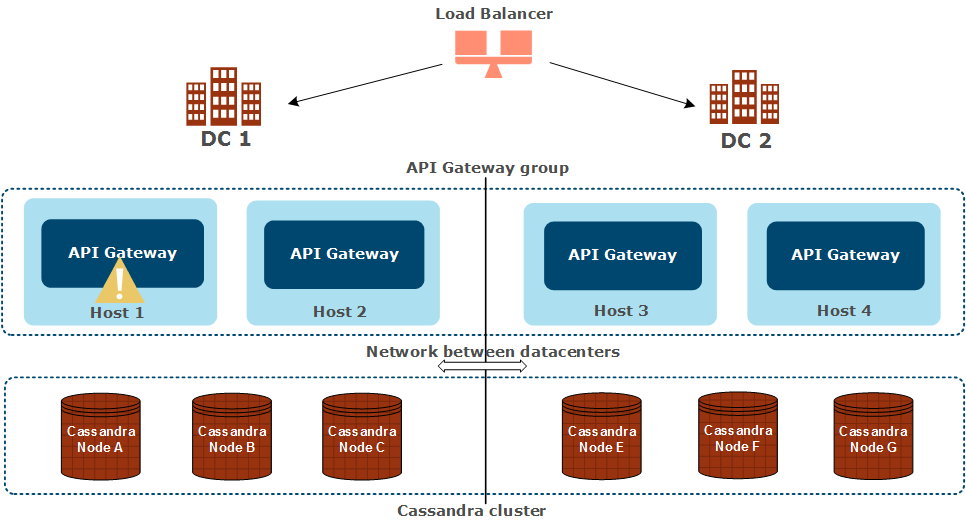
The following applies in this scenario:
- API requests can no longer be serviced by the API Gateway instance that is not running in DC 1.
- API requests will be serviced by the remaining API Gateway instance in DC 1.
- You must restart the API Gateway instance that is not running in DC 1.
One Cassandra node is down
In this case, one Cassandra node is down in DC 1:
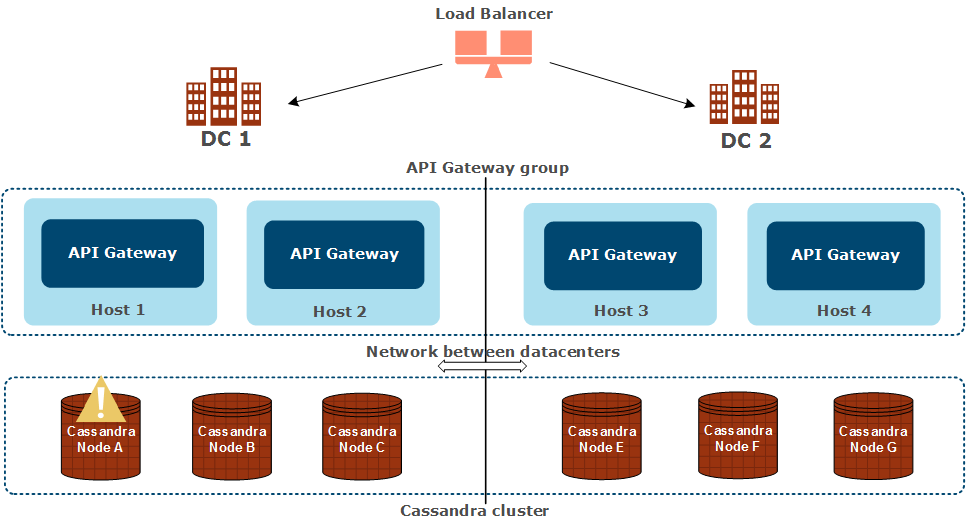
The following applies in this scenario:
- Cassandra is inherently HA and can tolerate the loss of one Cassandra node only in a datacenter (DC 1 in this case). This ensures 100% data consistency when Cassandra is configured for multiple datacenters. For more details, see Configure Cassandra for multiple datacenters.
- You must restart the Cassandra node that is not running in DC 1.
Note
When a node has been absent from a cluster for a time, it is brought back into the cluster after restart, and becomes eventually consistent by design. Node repair is required after re-integration into the cluster. For more details, see Perform essential Cassandra operations.A full datacenter is down
In this case, DC 1 is down:
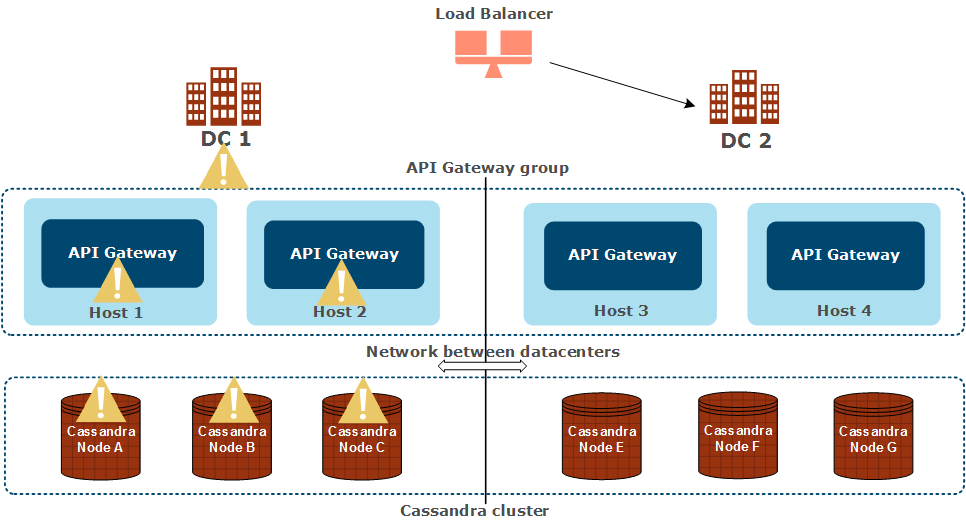
The following applies in this scenario:
- API requests can no longer be serviced by DC 1
- API requests are automatically directed to DC 2 by the load balancer
- API Manager quotas remain the same but over less servers
- You should not deploy updates for the following file-based data types to the API Gateway group:
- API Gateway configuration
- API Gateway KPS custom table structure
Caution
There is a risk that end-users may need to re-initiate sessions using the following data types stored in Ehcache:
- API Gateway OAuth token store
- API Gateway custom cache
Restart the datacenter
To restart the datacenter:
- Restart each of the Cassandra nodes.
- When all Cassandra nodes are running normally and have synchronized with the rest of the cluster in DC2, you can restart the API Gateway instances. The API Gateway should not be restarted prior to a successful restart of all Cassandra nodes.
Note
You should run thenodetool repair command on each of the three Cassandra nodes in DC 1 when the datacenter has been down for more than two hours.
The network between both datacenters is down
In this case, the network between DC 1 and DC 2 is down, while both datacenters remain active:
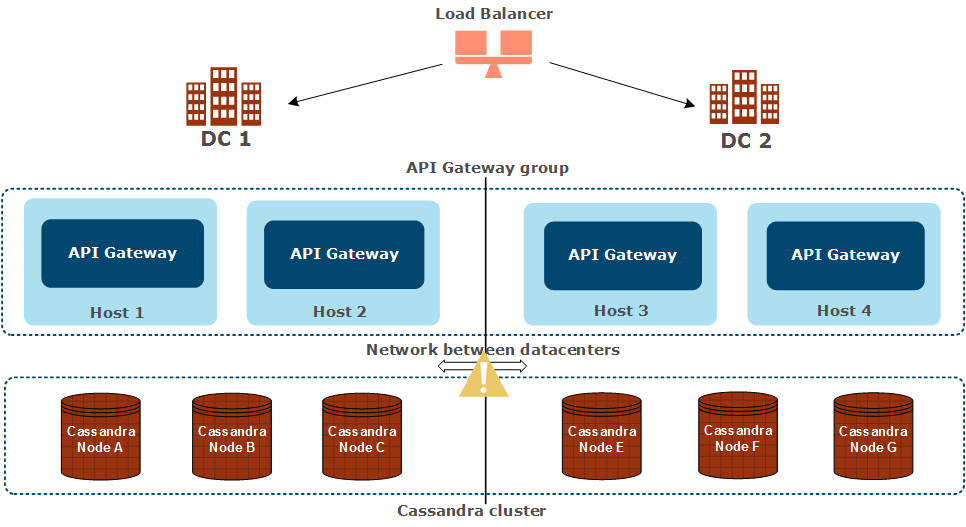
The following applies in this scenario:
- OAuth or throttling data stored in Ehcache per datacenter is not affected
- You should not deploy updates for the following file-based data types to the API Gateway group:
- API Gateway configuration
- API Gateway KPS custom table structure
- For the following data types stored in Cassandra, both datacenters are not synchronized until the network recovers, and then automatically resynchronize:
- API Manager catalog, client registry, web-based settings
- API Gateway KPS custom table structure
- For the following file based data types, a single API Gateway Manager web console cannot access both datacenters while the network is down, and can only access each datacenter separately:
- API Gateway logs
- API Gateway traffic monitoring
If the network connection has been down for more than two hours, the following steps are recommended:
- Run
nodetool repairon each of the six nodes in the Cassandra cluster to ensure that the data has synchronized. For more details, see Perform essential Cassandra operations. - Restart the API Gateway instances to resynchronize data from Cassandra (potentially in both datacenters if Cassandra changes have occurred in both datacenters).
It may take a minute for newly created, deleted, or updated APIs in one datacenter to synchronize successfully with the other datacenter.